Logging and events
23 Sep 2018Lets talk about logging.
import logging as log
if __name__ == "__main__":
log.info("Hello, world!")
Traditionally, Unix style applications have generated “logs” - records either on standard output or standard error of what the application is doing, when it’s received a request, what the request was for and soforth.
For instance, the venerable Nginx server used to host my blog generates a file by default named /var/log/nginx/access.log of records like this -
192.73.235.239 - - [16/Sep/2018:00:00:17 -0700] "GET /feeds/all.xml HTTP/1.1" 304 0 "-" "Tiny Tiny RSS/17.12 (bcdbfa7) (http://tt-rss.org/)"
69.162.124.230 - - [16/Sep/2018:00:01:06 -0700] "HEAD / HTTP/1.1" 301 0 "http://arrdem.com" "Mozilla/5.0+(compatible; UptimeRobot/2.0; http://www.uptimerobot.com/)"
93.104.109.176 - - [16/Sep/2018:00:01:16 -0700] "GET /feeds/all.xml HTTP/1.1" 301 185 "-" "newsboat/2.12.0 (Linux x86_64)"
77.178.120.26 - - [16/Sep/2018:00:01:27 -0700] "GET /atom.xml HTTP/1.1" 304 0 "-" "rss2email/3.9 (https://github.com/wking/rss2email)"
218.28.72.29 - - [16/Sep/2018:00:02:06 -0700] "GET / HTTP/1.1" 301 185 "-" "Mozilla/5.0 (Windows NT 5.1; rv:9.0.1) Gecko/20100101 Firefox/9.0.1"
Each one of these lines is a record of something happening in the system, in this case of the server successfully providing some content over HTTP to a requesting client.
As there are many kinds of events, there are many kinds of logs.
For instance Nginx also generates /var/log/nginx/error.log which records not successes but failures
2018/09/16 00:02:10 [error] 611#611: *25832 open() "/srv/http/arrdem.com/_site/blog/view/sc12--part-i--overview" failed (2: No such file or directory), client: 66.249.64.75, server: arrdem.com, request: "GET /blog/view/sc12--part-i--overview HTTP/1.1", host: "www.arrdem.com"
2018/09/16 00:20:06 [error] 611#611: *25891 "/srv/http/arrdem.com/_site/2015/09/28/thoughts_on_gratipay/index.html" is not found (2: No such file or directory), client: 46.229.168.143, server: arrdem.com, request: "GET /2015/09/28/thoughts_on_gratipay/ HTTP/1.1", host: "arrdem.com"
2018/09/16 00:30:14 [error] 611#611: *25974 open() "/srv/http/arrdem.com/_site/2014/11/28/the_future_of_the_lispm" failed (2: No such file or directory), client: 46.229.168.135, server: arrdem.com, request: "GET /2014/11/28/the_future_of_the_lispm HTTP/1.1", host: "www.arrdem.com"
2018/09/16 00:40:21 [error] 611#611: *25999 open() "/srv/http/arrdem.com/_site/blog/view/of-pseudotypes" failed (2: No such file or directory), client: 66.249.64.45, server: arrdem.com, request: "GET /blog/view/of-pseudotypes HTTP/1.1", host: "arrdem.com"
2018/09/16 01:17:57 [error] 611#611: *26179 open() "/srv/http/arrdem.com/_site/2012/12/27/idle-hands/semver.org" failed (2: No such file or directory), client: 66.249.64.75, server: arrdem.com, request: "GET /2012/12/27/idle-hands/semver.org HTTP/1.1", host: "www.arrdem.com"
2018/09/16 02:24:47 [error] 611#611: *26455 "/srv/http/arrdem.com/_site/2016/03/08/jaunt_deprecation/index.html" is not found (2: No such file or directory), client: 40.77.167.143, server: arrdem.com, request: "GET /2016/03/08/jaunt_deprecation/ HTTP/1.1", host: "www.arrdem.com"
Logs of events are useful, because they let you talk about the history of your system.
For instance syslog, the system log, strives to be a total history of the messages generated by your system.
Such a history is incredibly valuable when debugging problems which occur.
But what kinds of problems are we debugging?
In a traditional server, an application binds to a an address and port. This gives the application a file-like device for interacting with the network. As clients signal packets over the network to a computer running an application, they get buffered and
Such media is lossy, subject to physical failures and link degradation. The TCP/IP protocol is a standard for attempting to communicate messages over unreliable links. Typically have devices such as routers and switches in lines of communication, which introduce layers of buffering and message rewriting. At every step, messages are typically stored in fast volatile storage optimized for throughput with controlled mechanisms for discarding and failing to deliver messages if congestion gets too bad.
Even once messages are delivered to a server and re-assembled from fragments into wholes, as messages usually live in the context only of a single connection most systems don’t maintain a durable record of exactly what messages were received. The messages themselves are meaningless taken out of context.
In a network system like this, it’s possible to meaningfully digest the raw connections and messages which the server must be intimate to application level events which perhaps will be meaningful for localizing bugs. In fact it’s essential to debugging that some digest of inputs be persisted, because the inputs themselves need not be meaningful and bugs may depend on state and history of the system which cannot be meaningfully captured or inspected just with heap dump or inputs.
Not only do logs help you capture transient input state, they also help you understand what a program does.
Did you know that cp has -v aka --verbose mode?
$ cp -rv cider.el/* bar/
...
'/home/arrdem/cider.el/cider-apropos.el' -> 'bar/cider-apropos.el'
'/home/arrdem/cider.el/cider-autoloads.el' -> 'bar/cider-autoloads.el'
'/home/arrdem/cider.el/cider-browse-ns.el' -> 'bar/cider-browse-ns.el'
...
Without logs of what external effects a program had, it’s almost impossible to determine what it decided to do. Worker processed dying prematurely? Either they’re being killed, or something’s going wrong. Unless the parent process logs why it’s killing processes, or the children log why they’re exiting, there’s nothing to go on.
Structured logs are an evolution of simple logging, wherein the logs contain say JSON formatted data intended to be consumed again by another system. The advantage of such a structured logging system is that it becomes easier to record complex state into the log(s), and processing logs after the fact to inspect complex conditions becomes simpler.
Taking the value of values as a premise, it’s easier to inspect data and inspect pure repeatable transformations of data, as well as to inspect histories of data or even as data than to try and inspect a live stateful application with a microscope. While the data flowing through our system may be transient and useless for later inspection, the event log may be more meaningful or at least more approachable.
Logging, structured or unstructured, gives us a tool with which to view our stateful application as a data oriented, event driven and event producing system regardless of what state it may consume or effects it may produce.
Message queue systems such as RabbitMQ and RocketMQ attempt to provide an alternative to traditional socket based or shall we say “direct” client to server messaging by inserting a durable layer into the middle of the system. Durable queuing of messages in a system which can be operated reliably makes it much easier to design, deploy and scale a core application which may be more difficult to operate reliably.
Apache Kafka plays in the same space, in that Kafka aims to provide a general solution not just to message queuing and dequeueing, but to processing queues as “streams” of events which are also persisted for analysis. Kafka, like RabitMQ and RocketMQ is fundamentally a record of writes, which can be referred to by offset (write number) and viewed as a stream.
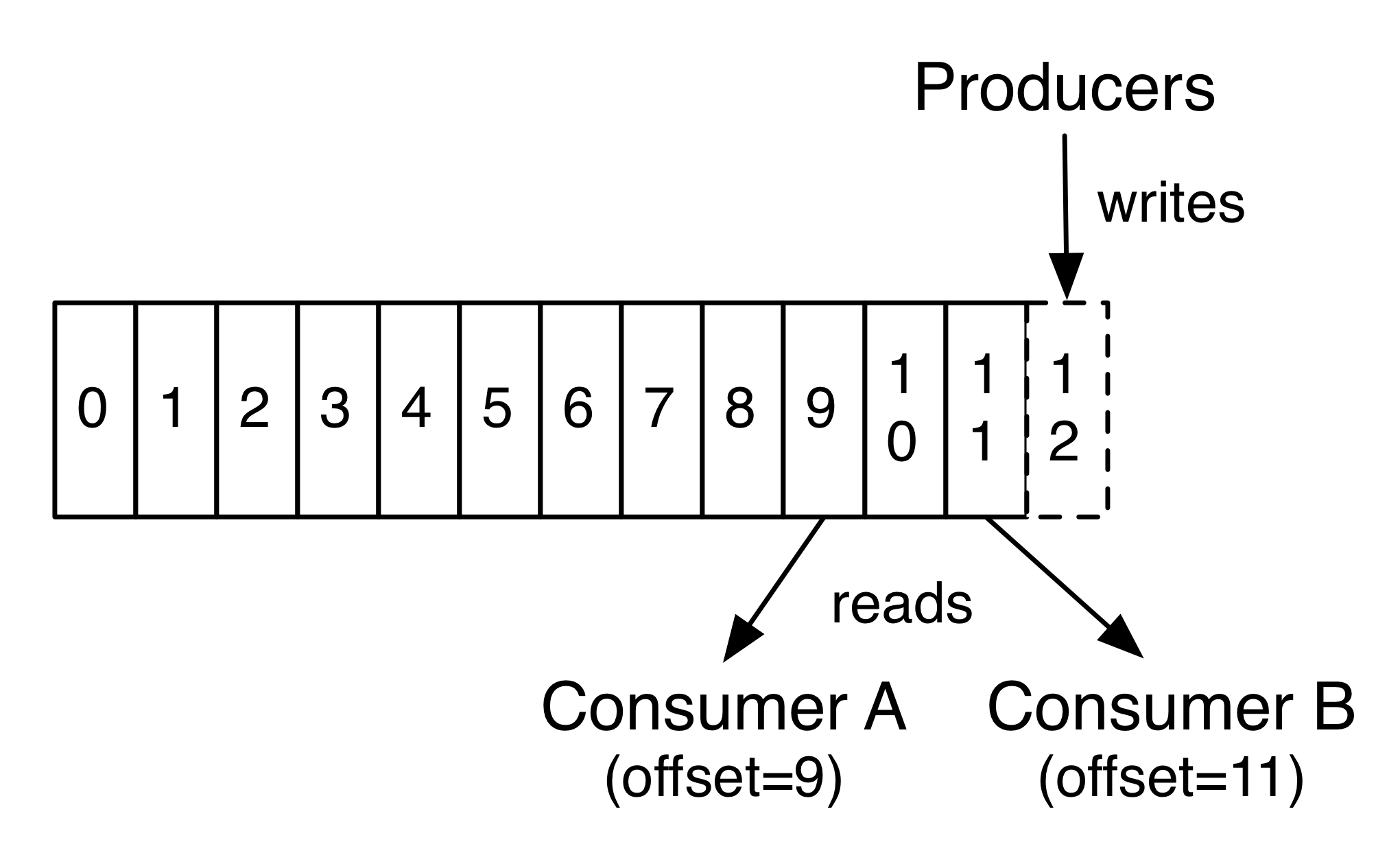 records in a steram</img>
records in a steram</img>In an effort to disambiguate these systems, usually referred to as event logs or write logs, from logging, our subject of discussion I’ll be referring to them as durable messaging or stream platforms.
In a traditional system a request to which an application cannot immediately respond would simply be discarded. For instance, a socket based system which suddenly faces more traffic that it can handle will simply fail either acknowledge connection requests or worse will accept connections but fail to issue responses before the connection times out. In either of these cases, the request becomes lost as the client either fails to make it, or the application’s degradation results in a failure to process. In a system built on durable messaging however, the request would become a message persisted to the queue which can then be processed whenever the backing application gets to it. The assumption being that a write-optimized scalable queue is capable of much higher throughput than all but the most carefully engineered applications.
This allows, for instance, write and async request scaling because records to be written can be cheaply recorded into the message queue, and eventually processed. Message queues are focused on delivery and latency, although they’re sometimes combined with other database systems to build systems with access to history in bulk. More in that shortly.
An example of a “pure” streaming system would be say a windowed join between two durable message queues, which produces its results to another queue.
I call this system “pure” because all if its inputs, outputs and state are stored in the stream system.
The stream processor is in pretty much every meaningful way a pure function of the messages in the stream(s).
You can have impure stream processing of course - programs which read from the stream system and export data say to standard out as does the kafka-console-consumer or systems such as kafka-connect which enable you to shovel data into Kafka from say a traditional database.
But what does this have to do with logging? The problem logging solves is not having visibility into the complex state of a running application, in the form of events which can be used to reproduce failure states. Metrics likewise attempt to help you get visibility into the dynamic state of an application, because the state of the application isn’t reproducible.
and logs? logs are technical debt made manifest. they are historically a mess of unstructured strings written out to disk. they have only enough context to hint at problems, no structure to perform operations or calculations on. and flushing to disk is a loaded gun in hand.
— Charity Majors (@mipsytipsy) May 21, 2018
Charity’s fantastic post Lies My Parents Told Me (About Logs) drives this home. Logs can never be simultaneously compact and rapid to query. They cannot be complete, and should they manage somehow to be complete they will not be cheap to store. Worst of all, logs will never be where you need them. The very act of inserting logging into an application is the act if attempting to presage where your problems will arise, and scry out what data will enable you to solve those problems when they occur. Not only is it aesthetically unpleasing in that it tightly couples your application code to the crosscutting concern of your logging implementation, and renders otherwise pure functional code bound to some particular I/O, you literally cannot get it right.
When building systems in a streaming data architecture, these concerns are almost entirely obviated at the application level. If you have a pure streaming system, which consumes streams and produces streams, all you need is tracing and record provenance. For instance on Kafka tools like Zipkin’s Kafka-clients can make achieving tracing of processing more accessible by maintaining a record of the correlation between records in the system, but in order for tracing data to be really valuable it has to be ingested into a join-optimized store beyond the scope of the streaming platform. There’s simply no need to use application logs in this way, when your application is itself a pure function from a stream to streams with all history persisted in the streaming platform.
Impure streaming systems also benefit from tracing and data provenance tools, especially if you work to push I/O to the boundaries and publish records of I/O back into the streaming system as normal events. Imagine a system which sends emails (an external effect) based on messages within the system. Simply by publishing a “confirmation” message back into the streaming system, it becomes possible to reflect on the history of what was actually achieved not simply what was requested although these could be assumed to be the same. This lets us treat an effectful system as if it were data oriented, and inspect is history as such. One could object that this is a horrendously inefficient way to talk about effects, but it turns out to be a surprisingly useful one.
There are ontological problems to be sure with the notion of an eternal, immutable append only log of events, but my experience writing functional programs and systems has confirmed over and over again that data oriented designs are simpler and easier to work with in the long run than the more stateful alternatives. So do go invest in Zipkin or some other tracing tool. Do go figure out how to take your nice κ architecture and reprocess data through it. Make it easy. Make reprocessing data and tracing how data processes through your topology the cornerstone of your workflow.
Don’t log. You already have a log. It’s your stream.
^d