The Silver Tower; A vision for computing
01 Apr 2019 “From study models — to cosmic vessels!”</img>
“From study models — to cosmic vessels!”</img>A project to imagine if not realize some of the benefits of functional programming in stream processing applications by vertically integrating a relocatable language, a topology programming API built in it with a compute scheduler.
Models of computation
There are two major models of computation present in the world - that of the Turing (or Turing-equivalent) machine, and the calculus of functions. The Turing/Von Neumann model presents a concrete machine which has state and transitions between state to describe computation. It is a tremendously successful model, and is the cornerstone of computer engineering as it has grown over the last decades as it gives programmers and engineers a framework for thinking about what a physical machine is doing.
The other model is broadly the functional calculus, particularly the Lambda Calculus of Church. This calculus is strictly equivalent to that of the Turing machine, but unlike the Turing machine which models state transitions, the calculus models evaluation by reduction as we’ve all seen in mathematics. Where the Turing/Von Neumann Machine has proved a successful engineering model, the Lambda Calculus has proved a successful theoretical model for analyzing and proving properties about data as it flows through evaluations.
Tools for computation
In the history of the computing industry, computers themselves have long been objects of study and great engineering effort. Just getting a computer to function - let alone do so reliably - has long been a difficult task. Computing resources (operations per second) and storage resources (durable and ephemeral) have all been rare, and communication links between computers have been unreliable and costly.
Rapid advances in the physical manufacturing processes and circuit design technologies - best known as Moore’s Law - has made it possible to tackle larger and larger problems using only a single computer; a single machine which can be approached using the Turing/Von Neumann model of the world.
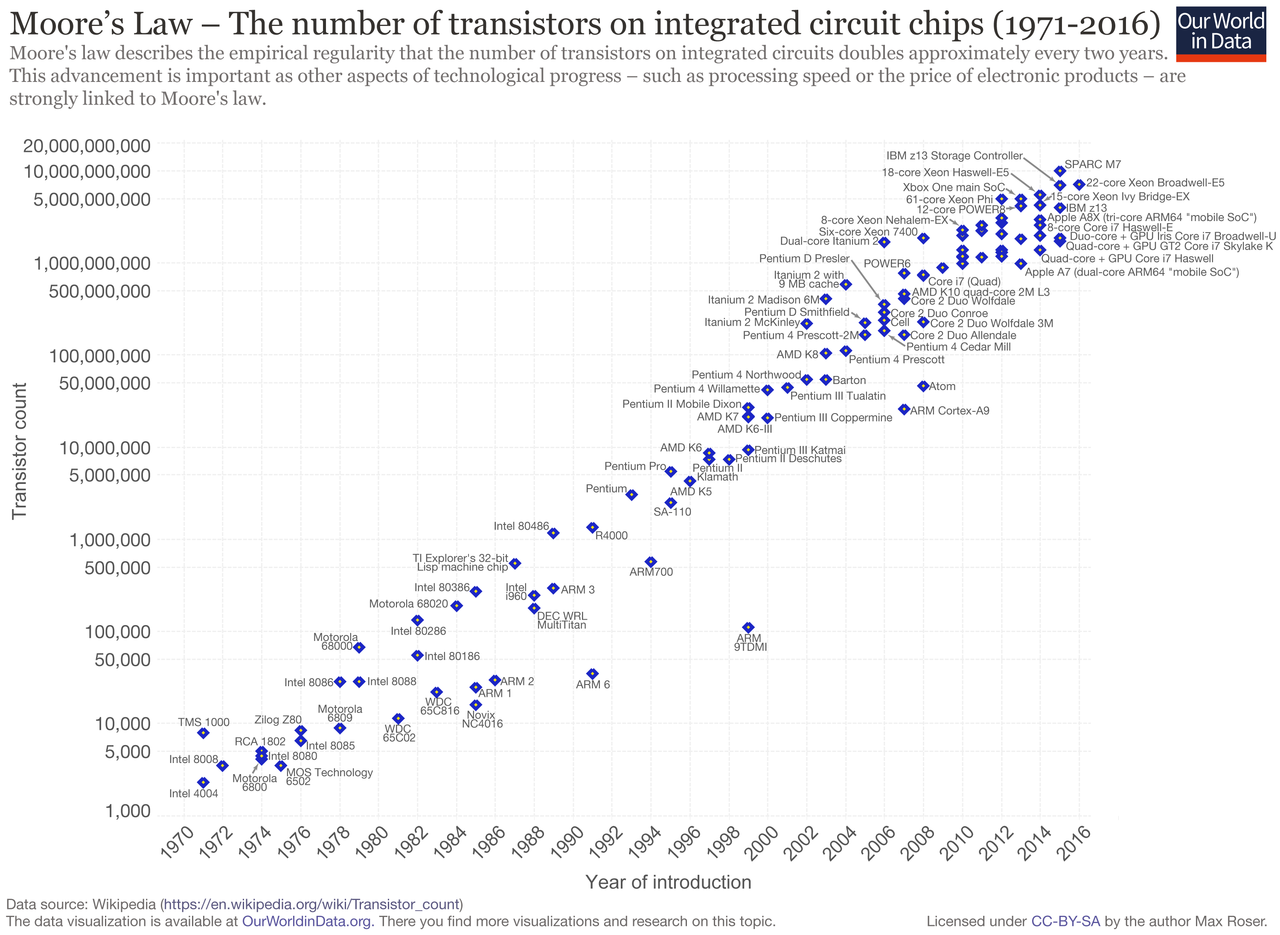
Recently however, processor manufacturing technology has reached physical limits. While advances in computing throughput are being made, they are no longer coming from pure manufacturing process changes and the overall rate of change in computing speed has slowed. While there are still performance wins to be had in hardware, more and more system designers have reached for parallelism (coordinating many machines “in parallel” on a single task) as the tool by which to achieve increased computing capabilities.
While the Turing/Von Neumann model of computation is convenient for a single computer, the amount of state with which a programmer must concern themselves grows exponentially both with the size of the data being manipulated by a program, and with the number of computers involved in processing. It is too precise a model of the mechanical implementation of computation. Particularly because the Turing/Von Neumann model is necessarily focused on the state of the machine, it makes developing reliable distributed computations incredibly difficult because it gives no framework with which to reason about what state is lost and must be recovered if a machine or computation fails. The entire state of every machine is inescapably of concern.
The Church / Functional (here and after simply functional) model of programming however describes computation as functions determined only by their inputs. A function in this model is completely independent of the process by which it is evaluated. It is also independent of the time and place of evaluation. This means a computation can be easily repeated if a machine fails - there is no required cleanup. It can be moved between computing machines to best utilize available resources or minimize transfer costs, and easily scheduled (or descheduled) to reflect the priority of computations on the system.
In summary, while the traditional Turing/Von Neumann “imperative” programming model has proved adequate in a world of single computers, the Church “functional” programming model has much to offer if one can apply its semantics to distributed computing environments.
Functions
Silver Tower is a vision of a pure but somewhat imperative computing system. In a Von Neumann computer, computation precedes as inputs are reduced to outputs. For instance adding two registers or writing a memory location in a traditional computer is non-reversible computation in that it has effects which destroy information - specifically the input to output relation.
In functional languages, computation occurs when expressions are reduced (evaluated) to their equivalent result forms which typically discards the production expression. However this begs the question of which expression gets evaluated first. Consider evaluating (+ (+ 1 1) (+ 2 3)). Do you first reduce (+ 2 3) to 5? Or do you reduce (+ 1 1) to 2? Both are data dependencies of the outer sum, so one must be reduced “first”. While this may seem an insignificant choice, the choice of reduction order has deep consequence. Expressions which reference themselves may never terminate under some evaluation schemes. There’s also a third option here - to delay evaluation entirely until some other expression absolutely demands the result of simplifying this expression. There are also hybrids of these approaches - “strict” evaluation order systems which feature selective “lazy” behavior. Strictness is convenient because it lends a clear mechanical model for how computation will occur, however laziness enables many approaches to formulating programs which would not be possible under eager evaluation.
In either case evaluation is said to be “pure” if there is no way for evaluation to produce consequences “to the side”, besides the loss of information occurring from reduction. For instance in a traditional programing language, one can write to an output stream which may be read by the user. The C++ snippet std::cout << "a message to the user\n"; would be an example of such an operation which writes “to the side” out to the user. Writing to a filesystem or otherwise creating machine state which cannot be reproduced is generally a side-effect.
Streams
A stream is a model for an ordered sequence of values and metadata about the values. A stream can either be computed - derived from another stream - or it can be observed from the outside world by a single agent.
For instance temperature measurements aren’t computed. They are sampled (observed) from the outside world, and seem to feature causality with respect to the observing edge system. To take an extreme case, two signals sent at different times and light-delays could be perceived to be simultaneous by appropriately placed observers. Their apparent causality is determined by the observing agent. So external events are said to be observed.
However, the moving average of a stream of temperature measurements could be a computed stream from another one, regardless of whether the stream over which the average is computed is observed or itself computed. Hence such streams are said to be computed.
Silver Tower is perhaps a strictly evaluated but pure language and programming environment wherein the only effect which functions in Silver Tower can have is that of sending messages. Technically sending messages doesn’t occur “to the side” - it’s only possible by returning messages (or batches). This means that it’s possible to track input to output relations between messages quite easily - the input values, their source streams and addresses therein are well known, and output messages can simply be annotated with this source information.
This is a deeply significant thing, because the implicit causal relationships between observed events cannot easily be revisited. Computations relying on reductions over streams for instance cannot generally be repeated if the contents of the underlying stream are re-ordered or become sampled due to later repartitioning (a retroactive attempt to add more observers and increase observer throughput at the cost of potentially changing causal orderings). However, computed results whose data dependencies and thus causality are known can easily be repartitioned and recomputed - although it may be a lot of work.
Introspectable computation
There are some other interesting properties this tracing of computed results grants as well.
For instance, it relieves the stream platform from persisting all computed results forever. As streams are defined as functions from input stream(s) to an output stream, results may simply be recomputed if they are needed again instead of being stored so long as the streaming platform records the functions which define streams. Some subset of results could even be stored, as users may deem appropriate if say the most recent values are often re-used.
Perhaps most interestingly, this model of computing mostly using derived streams gives consistency both to the computations which define streams, and to metadata about those computations. The tracing relations between inputs and outputs is one such example. Another is the ease with which other execution metadata such as timings and resource usage could be captured and made consistently visible as streams.
Repeatable - perhaps reversible - computation
The choice to relate outputs to their inputs combined with the choice to hang the entire system of pure functions makes it possible to work backwards from outputs to the values - perhaps history of values - from which they were computed. This accretion of values without discarding their relationship is a form of reversible computing - computing which preserves source information.
This may seem like an obvious result, and it is intended to be one, but its consequences are not. Most computing systems don’t perform reversible operations, nor do they rely on capturing nonrepeatable (observed) values into a durable form. This makes it incredibly difficult to unravel how errors occur, and to understand the behavior of the system. The core model of computation is based around discarding information which would make debugging possible.
A common response to this problem is to “add logging” - that is to attempt to capture a stream of logs from the system for later analysis. Unfortunately, this leaves the problem of what to log, as logging is additional side-effectful behavior which must be added. For a long form treatment of this, see my previous post. However by starting with a repeatable, stream (log) based system as the computing substrate, these concerns are obviated. Everything is always logged and traced - or at least that’s the presented computation model. Having those features in the core model, it becomes possible to back away from them. However without them they’re impossible to recover fully.
Topologies
In the Apache Kafka literature, these stream operations are called “stream processors”, or “nodes”. Processors connected by streams together make a topology.
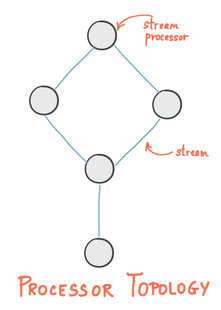
In Kafka, Pulsar, RabbitMQ and other traditional message brokers the streams which connect processors together are unchangeably named with global scope. This is because the programming model these systems assume is that messages cannot be regenerated if they are deleted, and because these messaging systems are designed to connect (and provide the state for) shorter lived applications, this makes sense.
However, it does result in a reductive at best model of topologies and streams, where the stream platform delegates to user applications all movement of messages between streams. Even conceptually simple operations like merging streams, sampling or teeing streams and renaming or aliasing streams are simply not supported by the major players.
It’s not that you can’t build these capabilities out, it’s that because they don’t exist and teams working to adopt these platforms have to imagine them many decisions are made in their absence. One particular example of this is coupling a stream processing application to the topics it processes by their name. One could imagine - were the streams of data primary not the applications processing them - that small general purpose topologies much like Unix tools could be stood up and most significantly reused across many streams. merge and tee for instance spring to mind as candidates for such transforms.
Being able to parametrize - perhaps to instantiate - topologies is not only of use with simple reusable components. Imagine wanting to test a complex topology which may retain state say in internal joins or other structures within the messaging system. Naively, testing such an application means providing it with a clean slate environment. One implementation of this would simply be changing topic names, or an application identifier used to compute internal topics every test run. While this succeeds at providing a clean slate environment, it prevents the detection of state based bugs. For instance inability to read the existing “production” application state could go un-noticed, as the test system may only see new format data. Being able to easily convey that a test application should be able to read data from the “real” sources, but should write elsewhere (eg. have copy-on-write topic semantics) would be invaluable for integration testing code changes.
Furthermore the ability to boot an application with copy-on-write topics begins to beg the question of what it means for a streaming application to be “in production”. If two topologies with the same purpose consume the same inputs, which one is “live”? The only reasonable answer is whichever’s output stream we choose to bless as canonical. Which has an interesting consequence. A “staging” application could be run at full scale against full production traffic transparently, so long as its outputs are directed elsewhere. One could even use the fact that both - even all - applications’ outputs are available to directly compare the behavior of multiple versions of an application.
Applications as ergonomic barriers
An interesting result is that the boundaries of a topology are somewhat arbitrary. Are two stream processors a “topology”? What about two “applications”, one of which processes inputs and the other of which processes the results of the first application? In every meaningful sense, these two applications are a single topology from the perspective of real end-to-end data flow.
In traditional stream processing systems such as Apache Kafka and Apache Pulsar, “applications” and “topologies” exist because stream processing occurs within the context of a delimited Unix process - a traditional application on a traditional computer - which implements what may be only some part of an overall data flow. This is because both the Kafka and Pulsar clients ultimately perform stateful network operations which are used to provide the semantic model of functional streams.
While this machinery is necessary to the implementation of a streaming system on current generation commodity computers, exposing this interface as the programming target brings stream programming from the pure functional level to a concrete Turing/Von Neumann model environment where it becomes much harder to focus on the function and data topologies because of the exposed implementation details.
Because stream processing in traditional streaming applications occurs within the context of Unix process, it may not be possible to experiment with data flows or data processing without going through the process of building an “application” implementing the stream processing machinery and its client driver and “deploying” it. The topology cannot exist independently of the concrete application and cannot be tested without it.
In most organizational settings, this means that one can’t simply write (or modify) a topology and drive it by hand interactively with data sampled from a real environment. Getting at staging or production data often means relocating a program from a developer’s workstation to some other controlled environment. Packing the program up to relocate it takes it out of the hands of a developer, typically makes interactive programming impossible and can take a meaningful amount of time (tens of minutes) whereas most interactive environments offer millisecond experimentation capabilities.
This leaves a huge ergonomic barrier to leveraging the potentially tremendous capabilities of stream processing systems. Applications which want to do stream processing are simply too hard to iterate on.
Furthermore having to relocate programs in order to test them undermines the semantics of testing and deployment. The purpose of testing is to observe the behavior of a program - implicitly making the claim that when we “use” the program, that it will exhibit the same behavior. This is a safe claim only if our programs depend on no context we do not control for when testing. For instance, were one to test a stream program against a stream driver with different behavior than that used in production, the tests may not be predictive of all production behavior. The only solution to this problem is not to change the machinery which we use to drive our programs. It must be possible and easy to drive streaming programs using example data using the same machinery which will drive data through the program when it runs “for real”. We must eliminate any differences between a development, test and production setting.
One solution to this problem is to abandon the notion of “applications” as the unit of development. What if evaluating a function committed it into the compute platform rather than into local process memory? Evaluating an expression which produces a stream processor would implicitly interact with the cluster scheduler, as would connecting that stream processor to inputs and outputs. Connecting a stream processor to a local data set would only force the function to be schedule for local execution. Connecting it to a remote data source - say staging traffic or a sample of production - could cause remote execution or local execution. This is possible only if the language level evaluator captures enough context about programs and program evaluation that it’s possible to automatically generate the packaging necessary to achieve code relocation.
Database equivalence
we need an llvm of relational algebra to be honest
— Cody☕️🦀🏔 (@valarauca1) April 1, 2019
I adored Nikolas Göbel’s talk on his incremental datalog system at Clojure/Conj 2018 (video) because it touches directly on the semantic equivalence of operating a “query” over a fixed data set such as a database and over a stream of novelty. This was something I observed while putzing with shelving, and have wanted to explore myself.
As this post is already too long I must skimp on the details somewhat and refer you instead to the excellent literature on Differential Dataflow (McSherry et. all 2013), but a streaming compute platform provides a natural substrate for the implementation of both traditional streaming query systems and fully incremental queries as live topologies within the system and make readily accessible the tools required to build for instance incremental materialized views, hand-planned queries and other such capabilities.
Conclusion
There’s little new in this essay. Reversible computation, distributed tracing, distributed functional programming, streaming databases - all of this has been done before.
What I hope is novel is even the dim vision of an abstractly uniform grid and stream computing future, and the expression of the various wins it makes possible by breaking down the current application vs database siloing without loss of semantics or generality.
^d