Homelab: A PDU arrives
07 Jul 2019In my first homelab post, I mentioned that I chose the AMD Ryzen 5 1600 processor to run my compute nodes. Unfortunately, the Ryzen series is vulnerable to random soft locks which doesn’t seem to have a workaround other than “don’t let them idle”, and I neglected to do my do-diligence when I purchase this hardware platform because I trusted @cemerick who owns a whole stack of nearly identical boxes.
I started noticing because, having cut over to my internal DNS after a couple days of leaving the lab alone suddenly my internet connection seemed really slow or didn’t work at all because all my DNS resolvers were non-responsive.
Everyone who’s ever worked in operations has horror stories of hosts with the longest uptime. Machines which ran for years without maintenance. Machines which were forgotten altogether. Ironically, I have the opposite problem. Because my Ryzen boxes lock up at random on a timescale of about every two days, I can’t even get to the point of running “reliable” computations or servers by leaning on the underlying host to be reliable.
There’s a really interesting meditation to be had here on how absurdly reliable the hardware we take for granted is.
Even commodity hardware can reasonably be expected to stay on for years, adding and executing instructions correctly, without meaningful interruptions.
Only on the scale of large datacenter deployments do cosmic ray strikes, hardware failures and other “rare” events become common.
An average programmer takes for granted that the network will mostly work, and that 2 + 2 will always be 4 with no need to cross-check results.
Because that’s how good hardware is.
Gone are the days of the Intel floating point bug(s) and dealing with write errors on shitty disks.
To put this another way - computers are reliable enough that for many applications you don’t have to go wide. Scaling vertically (just buying a bigger computer) really works for a long time and likely buys you all the reliability non-real-time, non-streaming workloads actually require. Furthermore Google’s offering of live migration of client VMs means in the cloud you can achieve truly insane application uptimes. Or go buy the biggest POWER 9 box you can get your hands on.
In an environment where hardware failures are common (like mine!) you have the opposite problem. In the omnipresence of hardware failures, everything has to be designed to die randomly at any point and recovery has to become automatic. In short, all the problems which usually show up only “at scale” come calling, which I think is really interesting because it means you can’t make the huge mistake of being able to lean on an incredibly reliable piece of hardware.
A real problem facing software systems is that vertical scaling works. To a point. And when that line in the sand is crossed, the software architectures and patterns for achieving reliability are completely different. Either you wind up paying IBM or Oracle an absolutely unbelievable amount of money for a magical sufficiently reliable machine, or you have to likely redesign your entire system to operate in a different less reliable environment. Neither is a good or easy outcome. The only serious choice seems to be designing for distributed reliability by default, because the cut-over can be so painful.
Okay. So back to the lab. I’ve got machines which get wedged, and don’t respond to commands. What the hell am I gonna do. I sure don’t want to come home and push power buttons every day. What happens when I go on vacation? The lab’s just gonna die?!
Well the Industry Grade™ solution to this problem is to use the BMC controller - a microcontroller built onto server class motherboards which provides “baseboard management” such as power control over a separate software stack and sometimes network link - to remotely power off and power back on wedged boxes. It’s not pretty, but it sure does work.
As Rich Hickey and Joe Armstrong have both eluded, the most consistent problem in computing is not being able to reason about the state of the machine. Resetting that state to nothing and allowing it to recover into known states is the ultimate big hammer of problem solving.
Okay but motherboards with BMC controllers and IPMI are uh not features on the commodity motherboards I went with. So what’s plan B? Enter the networked Power Distribution Unit (PDU).

Your common-or-garden surge protector is an example of a PDU. It just provides distribution of power to a bunch of sockets.
A networked PDU (sometimes called a managed PDU) goes a step farther and provides per-socket software switching. Expensive models even provide per-socket power usage metering, allowing datacenter operators to implement per-host power chargeback. For my usage, I settled on an APC 7900 unit which I scored used on ebay at a meaningful discount decommissioned from someone’s datacenter.
Using a my PDU (named sucker because this is a sucky solution to a sucky problem), I can configure my three hosts’ BIOS to automatically power on after power is restored, wire my hosts power through the PDU and given appropriate automation power cycle the hosts when they get wedged.
Implementing this is remarkably easy.
The PDU can be configured to expose a management console over the telnet protocol, so all one has to do is know what ports on the PDU each host are plugged into.
Adding the PDU to my internal DNS and telnetting to it, we’re welcomed by a screen which enables exactly my use case -
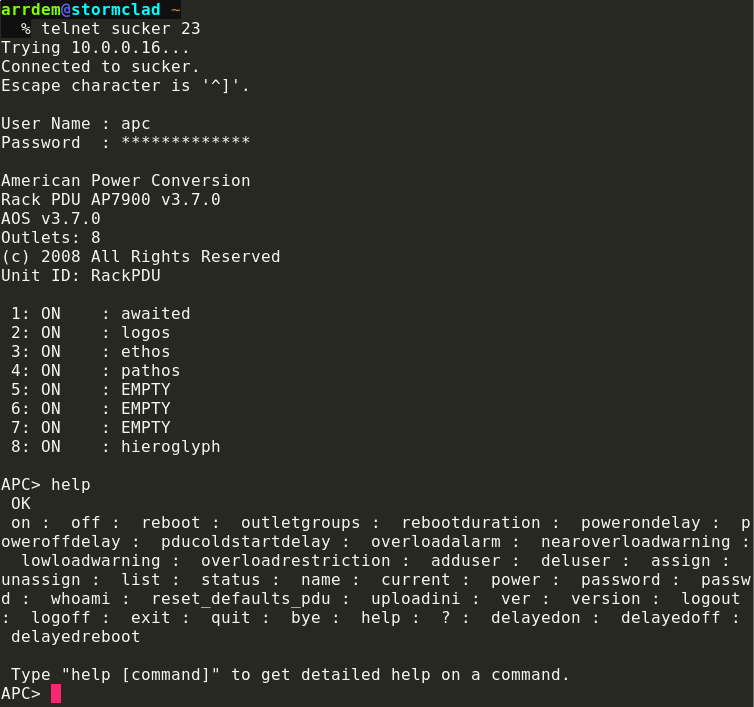
All one has to do is punch in reboot 2\r in order to reboot logos.
Implementing this reboot in Python is pretty forwards.
Really you just need to use the telnetlib and on recent versions of Python you’re golden.
Maybe something like this -
from telnetlib import Telnet
CONFIG = {
# APC PDU credentials
"pdu_username": "apc",
"pdu_password": "[REDACTED] -c",
# Hosts recover in about 40s,
# But only stop responding to pings for about 6-8s.
"debounce": 40,
# Once a host is up, 5s of no ping is indicative.
"threshold": 5,
# (hostname: PDU port) pairs
"hosts": {
"logos": "2",
"ethos": "3",
"pathos": "4",
# "ketos": "5", # the final mode
}
}
def do_reboot(port: str):
"""telnet to sucker, reset the port and log out."""
def apc_login(conn):
conn.read_until(b"User Name")
conn.write(f"{CONFIG['pdu_username']}\r".encode("utf-8"))
conn.read_until(b"Password")
conn.write(f"{CONFIG['pdu_password']}\r".encode("utf-8"))
def apc_command(conn, cmd):
conn.read_until(b"APC>")
conn.write(f"{cmd}\r".encode("utf-8"))
# To ensure only one process logs into the PDU at once
with Telnet('sucker', 23) as conn:
apc_login(conn)
apc_command(conn, f"reboot {port}")
apc_command(conn, "quit")
Here, I’m using the telnetlib’s nicest feature - expect-like patterns. telnetlib supports waiting, reading from a connection, until it gets a sequence like a shell prompt back. This helps you write clients which interact with command protocols - like my APC shell - which dump a bunch of data then prompt and may not gracefully handle inputs before the prompt is sent.
We could clean this code up somewhat by introducing a “real” expect function -
def expect(conn, text):
offset, match, data = conn.expect([bytes(text)], timeout=1)
if offset is None:
raise Exception("Unable to match pattern {} in conn {}".format(text, conn))
else:
return
I don’t need perfect - for now I just need done so I can stop manually remediating these softlocking boxes.
So what criteria do I want to use for my host(s) becoming nonresponsive?
Well one criteria is not returning ping responses.
It’s not an ideal criteria because ping isn’t actually a service I care about and moreover some hardware supports offloading ping responses to the network card so a host could return a ping response while being stuck.
All my boxes are DNS resolvers, which means they should accept a connection on port 53.
All my boxes run SSH, so they should also accept a connection on port 22, and print an SSH banner.
So we can bolt some fragments together -
from subprocess import check_call, CalledProcessError, DEVNULL
from telnet import Telnet
def ping(hostname: str,
count: int = 2,
timeout: int = 1):
"""Send count packets to a hostname, with a timeout of timeout"""
try:
return check_call(["ping", "-q",
"-c", str(count),
"-W", str(timeout),
hostname],
stderr=DEVNULL,
stdout=DEVNULL) == 0
except CalledProcessError:
return False
def check_port(hostname: str,
timeout: int = 1,
port: int = 22,
banner: bytes = b""):
"""Knock on the given port, expecting a banner (which may be b'')."""
try:
conn = Telnet(hostname, port)
offset, match, data = conn.expect([banner], timeout=timeout)
conn.close()
return match is not None
except ConnectionRefusedError:
return False
def knock_ssh(hostname: str):
return check_port(hostname, port=22, banner=b'SSH')
def knock_dns(hostname: str):
return check_port(hostname, port=53, banner=b'')
Okay so now we’ve got the machinery for doing a reboot and for checking a host’s “health” in hand. We just need to wire it up into some threads.
import logging as log
from datetime import datetime, timedelta
from threading import Thread
from time import sleep
def zdec(i):
"""Decrement, witha floor at zero."""
return max(i - 1, 0)
def monitor(hostname: str, port: str):
log.info("Monitoring {hostname}".format(hostname=hostname))
threshold = CONFIG["threshold"]
debounce = timedelta(seconds=CONFIG["debounce"])
# Outer loop - never exits just restores state
start = datetime.today()
counter = 0
while True:
now = datetime.today()
delta = now - start
# Debounce - provide a pause inbetween interventions to allow the host to stabilize
if delta < debounce:
pass
elif counter >= threshold:
# Bounce the box, wait for it to become healthy again
uptime = delta.total_seconds() - counter
log.critical("{hostname} detected unhealthy for {counter}s after {uptime}s up, forcing reboot!".format(**locals()))
do_reboot(port)
start = datetime.today()
counter = 0
elif not ping(hostname) or not knock_ssh(hostname) or not knock_dns(hostname):
# If the hostname is unhealthy, we increment its "bad" score
log.warning("{hostname} detected unhealthy ({counter} of {threshold})".format(**locals()))
counter += 1
else:
# Otherwise we zdec the score.
counter = zdec(counter)
# delta > debounce implied by if ordering
if delta.total_seconds() % (60 * 5) // 1 == 0:
log.info("{} healthy for {}s".format(hostname, delta.total_seconds()))
sleep(5)
if __name__ == "__main__":
for hostname, port in CONFIG["hosts"].items():
t = Thread(target=monitor, args=(hostname, port))
t.start()
We’ll make a thread for each host in the config, and that thread will sit in an infinite loop running health checks every 5s. If the host is unhealthy for 25s, we’ll use the PDU to force it to reboot. My hosts take about 40s to come back up when hard rebooted this way, so if we assume that detection is accurate I’m taking an outage of about 65s maybe every day or so. 65s over 24h is 99.92% uptime! Three nines! Webscale!
By simply running an instance of this script on each node, I can make just my three node cluster watchdog itself. That’d enable my cluster to detect and recover from a single or double fault. Which would be a huge improvement in my cluster’s reliability! My odds of having all three boxes lock up at once given recoveries of single and double host failures are really slim - about 0.00000004% if I’m doing my math right.
Of more concern is that there’s no coordination in this script! If two hosts are good and one host is bad the bad host will likely get power cycled twice. Worse, the race condition between two un-coordinated hosts trying to reset the same box at once could easily generate exceptions telnetting since my PDU only accepts one connection at a time.
Either I could use a distributed consensus system like Apache Zookeeper, or I could figure out how to only run one instance “vertically scaled” to enough nines like I slagged on before.
It just so happens I’ve had a Raspberry Pi B+ sitting around waiting for a rainy day. In fact I’ve got a whole stack of them at this point.
#homelab now with a bunch of raspberry pis from @AndySayler pic.twitter.com/LL2ulHT7Gt
— arrdem (@arrdem) July 4, 2019
Enter rikis-hopuuj.
The name is deliberately meaningless.
In fact, it’s a proquint - a word in a constructed language designed to make 16 bit chunks enunciable.
Two 16 bit segments joined on - to make the 32 bit value 12187675381 to be precise.
I’m not sure proquints themselves are The Right Thing - but being able to generate random identifiers and make them somewhat more tractable by humans (unlike UUIDs which are relatively intractable and unenunciable) is an interesting concept.
Astute python programmers following along so far may have noted that I’m making extensive use of Python’s String.format method, and doing so taking locals() (the map of all local variables to their bindings) as keyword arguments.
This is weird python at best.
It’d be better to use Python’s f-strings which I must admit are one of the best new features besides type syntax in the 3.X series.
Sadly f-strings are only supported in Python 3.6 and later, and my poor little raspberry pi runs Rasbian (Debian) which packages Python 3.4 so I have to make due.
However with a Power Over Ethernet (POE) dongle to power rikis-hopuuj off of my fancy switch and a simple systemd unit -
$ cat /lib/systemd/system/pdu-monitor.service
[Unit]
Description=Monitor the network, restarting boxes
[Service]
ExecStart=/usr/bin/python3 /root/monitor.py
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
I’m all set!
PDU demo pic.twitter.com/KvFL2d44rP
— arrdem (@arrdem) July 7, 2019
Next time I’ll look a bit at solving the “vertically scaled” monolithic monitoring problem, and starting to play with Zookeeper.
^d