Homelab: Inventory
14 Jul 2019Previously, I talked at some length about the slightly heinous yet industrial grade monitoring and PDU automation solution I deployed to keep my three so called modes - ethos, logos and pathos - from locking up for good by simply hard resetting them when remote monitoring detected an incident. That post (somewhat deliberately I admit) had some pretty gaping holes around configuration management for the restart script. The restart script is handwritten and hand-configured. It has no awareness of the Ansible inventory I introduced in my fist Ansible post - which captures much of the same information. Why the duplication?
The answer is simply that I think the question of how you manage inventory and configuration as it relates to inventory is a deeply interesting question.
Let’s do a quick refresher on Ansible’s notion of inventory first. In Ansible, there are hosts, and groups. Groups contain either other groups (as children) or hosts (also as children), and may have vars (key/value pairs). Hosts exist, and also have vars. When Ansible executes against a host, the host is “materialized” by merging all the vars set on the host, or on any group of which that host is a member and using that set of bindings.
By way of a quick demo -
---
# This file is ./demo-inventory
group_a_b:
vars:
a: b
hosts:
foo.demo:
group_c_d:
vars:
c: d
hosts:
foo.demo:
Here, we’re creating two groups, each of which apply a key/value pair to what happens to be a single host.
And if we run it, we’ll see that the vars are in fact merged -
$ ansible-inventory -i demo-inventory --list | jq .
{
"_meta": {
"hostvars": {
"foo.demo": {
"a": "b",
"c": "d"
}
}
},
"all": {
"children": [
"group_a_b",
"group_c_d",
"ungrouped"
]
},
"group_a_b": {
"hosts": [
"foo.demo"
]
},
"group_c_d": {
"hosts": [
"foo.demo"
]
}
}
Other data sources
Recall, that Ansible features both host_vars and group_vars as shall we say tack on sources of data.
Respectively, these directories may contain YAML files named for hosts or files named for a groups, providing vars as an alternative to writing those vars out in the hosts (inventory) file.
vars_files
Another trick you can play is telling Ansible to bolt on yet more vars using vars_files.
---
# snipped from play.yml
- hosts:
- ...
vars_files:
- "vars/defaults.yml"
- - "vars/_.yml"
- "vars/.yml"
roles:
- ...
vars_files as with so many Ansible features is under-documented.
The parameter itself is a sequence of additional files to be loaded and from which to source additional host level vars.
The trick here is that nested lists of files are also supported - in which case the first file which exists will be loaded. Here, I’m using this trick to load either a distribution release specific vars file, or a distribution specific vars file. The distribution specific file is a fallback with respect to the more specific file, but the defaults are always applied.
This is a good trick, which provides one way to go bolt on your own sources of data.
Custom inventory
The real trick is that you can write your own inventory scripts. Hate YAML? Got your own data source? Want some other model? You can just build it yourself and bolt that onto Ansible! No need to go mucking around with Ansible’s opinions about stuff and things.
I can’t commend the Python API for defining inventory scripts whatsoever. I think it’s a tremendously undocumented, complicated, and generally more bother than it’s worth - but there exist some examples of using it.
On the other hand, the JSON API for interfacing with arbitrary external inventory sources is tremendously clear cut.
Simply, it’s the same JSON format I’ve been using to show you what’s “really” going on - with the addition of vars mappings being supported on groups so you don’t have to materialize all the host vars into _meta yourself.
Technically you don’t even have to do the _meta dance, Ansible will run your script a bunch of times with --host if you don’t.
All a script has to do is accept either --list and dump everything (same as I’ve been using ansible-inventory --list) or --host=<hostname> to just get (all of!) one host’s vars when all the groups are applied.
This gives us an out, if you want to define some other model (or use other data sources) and map it into the Ansible host/group model. Ansible itself includes a huge collection of “contrib” inventory scripts, for sourcing hosts and vars from any and every compute utility tool you can name - like DigitalOcean’s for instance. There’s even another whole collection of more official inventory scripts, like k8s.
The only other tool for injecting vars into the an Ansible play is to define custom facts.
Custom facts
When Ansible runs the first thing it does is run the setup module.
The setup module executes any executables in /etc/ansible/facts.d/ expecting that they produce JSON output, and loads any non-executable files in that directory again as JSON.
Each of the JSON blobs generated by or read from /etc/ansible/facts.d is keyed by the name of the file or script it came from, and that entire map from filenames to data is made available in Ansible as the ansible_local var.
To take an example, if ethos had the JSON blobs /etc/ansible/facts.d/{foo,bar}_facts, the ansible_local var would look something like (in YAML)
---
foo_facts:
foo: bar
bar_facts:
bar: baz
Facts are a way to pull data down from the hosts themselves - device IDs, uptime or other unique machine specific state (possibly even “facts”) unsuitable for vars maintained in inventory.
Modeling with inventory
Okay so we’ve got some tools. We have hosts, groups and vars which can easily be generated by some user defined software, and technically also facts which - aren’t second class but require much more forethought. My gut is that group and host vars as files is probably better treated as an accident of the implementation rather than an essential tool. Likewise the relative difficulty of deploying and gathering facts suggests that facts aren’t a fantastic modeling tool unless you have really specific needs.
This leaves the inventory structure, with its groups and inline vars potentially derived from other sources. That we can do a lot with.
So let’s think about my homelab for a bit. The thin black lines are network connectivity, the thick red lines are power, and the one green line is the battery’s USB read port.
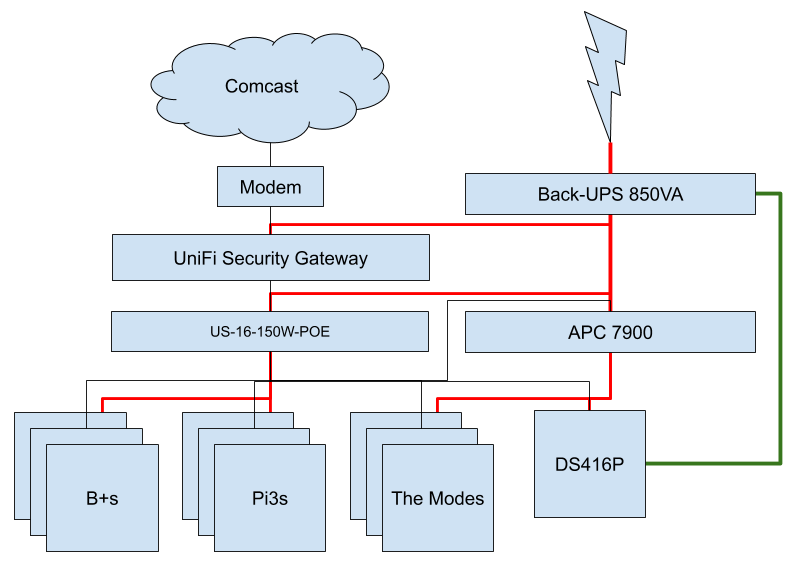
One entire concern in inventory which is worth modeling potentially with groups is failure domains.
Failure domains
Simplifying somewhat, my lab has a single public internet uplink. That one uplink has a USG router and a 16 port switch inbetween it and pretty much everything else. Then all my various computers are hung either directly off the switch, off wireless APs hung off the switch or one daisy chained unmanaged switch out in the living room for the PS4.
So really from the perspective of my networking gear, I have an entire stack of single devices. A failure of either my uplink, or my router, or my switch would destroy a meaningful amount of my internal connectivity. So all of that has to be working.
A crosscutting concern is that I have a single power source - although home solar would be neat - and a single backup battery. That one backup battery has some devices hanging off of it, but the majority of the compute resources hang off the networked PDU I wrote about last time. So again, I have another daisy chain of devices on the power front. Sure the backup battery gives me a fairly surprising amount of reliability in the face of thunderstorms or me deciding to unplug the whole rack and move it, but if that battery goes everything goes.
In the compute-as-a-utility world, this would be described as being a single failure domain. The notion of a failure domain is simply that it’s a group of hardware which due to shared network infrastructure and power infrastructure will fail all at once.
There’s a pretty decent Azure blog post (2015) which presents a diagram of the datacenter’s network architecture.

In this diagram, TOR is an abbreviation for “Top of Rack (switch)”, for rack presumably being a standard frame usually having 48 “units” or 1-inch mounting slots. A common design is to put a small (1 “unit”) switch at the top of the rack, wire everything in the rack to that switch, and then connect the switch to whatever the broader datacenter network topology may be with only a single uplink from the switch.
You’ll note that in this diagram, TOR switches seem to be connected to multiple “spine” routers. Interestingly, Microsoft’s diagram actually shows a full mesh where every TOR is connected to every spine - where a spine is presumably some sort of intermediary router. This is an unusual design, but having multiple uplinks from a rack to shared routers with some sort of routing mesh above that adds resiliency against single shared router failures. Multiple paths to any given rack mean multiple failures are required to take the rack down.
Most compute-as-a-utility vendors go even farther than this, and offer many failure domains (sometimes called availability zones or simply zones). Some of the bigger vendors also offer groups of availability zones called regions across which shared load balancing and and instance scheduling are offered. Google for instance provides an exhaustive list of all the zones and regions in which Google is happy to rent you resources.
To finish providing a model - having hosts be members of racks, and racks members of rack groups, which in turn live under “shared networking” groups and within power groups and finally sites which are comprised of shared power and networking groups live within regions. The really nice thing is that if you want to extend this model, you just add another tree of groups.
Placing a host into a service cluster can be a declarative thing.
For instance I’ve toyed with wiring up service groups ala service_<servicename> to generate DNS A-record round robins automatically so that all I have to do is run a playbook like
---
# Install the service
- hosts:
- service_myservice
roles:
- role: myservice
# Update the DNS record(s) -
# Inspect all groups for "service_" prefixed
# groups when generating a zone, and assume
# that every service_ group gets an A record
# with the IPs of its members.
- hosts:
- service_dns
roles:
- role: dns-zones
In a shared infrastructure environment, hardware is provisioned in batches or requests to customers, who presumably use it to run services. You could try to model a hardware allocation workflow by creating a group for the results of every request. This lets you keep provisioning metadata around at the unit of provisioning - some sort of batch request.
Heck - Ansible supports using directories as sources of inventory. So you could even put the provisioning history / state data in a different file or directory and lock that file down to some combination of automation and the blessed provisioning administrators.
I’m not sure how far this group model goes, but it’s interesting to consider how far you can stretch the consistency wins of preferring groups and managing set theoretic memberships to managing key-value storage.
A case study
As an exercise, let’s refactor my inventory to reflect this structure. I’m gonna deliberately avoid putting vars on hosts wherever I can, and instead attempt to put vars on groups so that hosts almost strictly inherit vars. I think this helps make state manageable in the long term, because it groups related sets of vars into one place and makes it harder to make local changes.
Note I’m gonna use the doc: key, which is ignored by Ansible’s inventory language to write notes into this inventory.
WARNING It should also be noted that assigning attributes to hosts via groups is an extension to the Ansible inventory system that’s specific to the YAML inventory notation. Sadly - I think it’s a great feature. See the source.
---
# My general pattern for naming groups is that
# groups are {groupname}_{value} and define
# var: {groupname}: {value} along with any
# other key/values. This makes it possible to
# go back from a random host to the group(s)
# of which it is a member.
region_na:
doc: |
This exists entirely to specify what
assets I have in North America. Somewhat
silly, but I'm trying to lay out a pattern.
vars:
region: na
children:
geo_apartment:
geo_apartment:
doc: |
This group exists to map the physical
facility of my apartment to a collection
of failure domains.
vars:
geo: apartment
children:
# I don't have any redundancy, one AZ
az_apartment0:
uplink_comcast0:
doc: |
This group describes a single network
uplink to a provider. Ideally a high
reliability site would have redundant
uplinks.
vars:
uplink: comcast0
children:
az_apartment0:
power_xcel0:
doc: |
This group describes a single power
substation, and the hardware attached to
it. A highly reliable site would ideally
have multiple power supplies - backup
batteries excluded - and in some extreme
cases such as telecom systems may
be connected to multiple regional power
generators not just redundant substations.
vars:
power: xcel0
substation: gunbarrel
children:
az_apartment0:
az_apartment0:
doc: |
This group packages "racks" or just chunks
of my hardware deployment into a failure
domain which is associated with a network
uplink and with a power supply. You could
extend this same model to talk about
cooling for instance.
vars:
az: apartment0
children:
apartment_rack0:
apartment_rack1:
apartment_rack2:
pdu_ups850_0:
doc: |
This group contains devices which pull
power directly from the UPS. In which
sense it is a "power dist. unit"
vars:
pdu: ups850_0
hosts:
sucker.apartment.arrdem.com:
pdu_sucker:
doc: |
This group defines a collection of hosts
which are all wired to the same PDU, the
connection details for the PDU (or some of
them) and the mapping of PDU port(s) to
devices because well that's defined at the
PDU level by physical connections.
vars:
pdu: sucker
pdu_uri: sucker.apartment.arrdem.com:23
hosts:
logos.apartment.arrdem.com:
pdu_socket: 2
ethos.apartment.arrdem.com:
pdu_socket: 3
pathos.apartment.arrdem.com:
pdu_socket: 4
hieroglyph.apartment.arrdem.com:
pdu_socket: ...
pdu_us16150w_0:
doc: |
This group contains devices which pull
power over PoE from my PoE switch.
vars:
pdu: us16150w_0
children:
# Racks 2 and 3 are PoE'd RPis
rack_apartment_2:
rack_apartment_3:
hw_ryzen0:
doc: |
The hw groups just define groupings by
hardware type. It so happens that I'm
using racks as chunks of one hardware
platform - typically three of a kind.
It so happens that rack '1' is all Ryzens
In other hardware deployments, this could
be far less trivial with mixed host
platforms per rack being common even.
vars:
hw: ryzen0
children:
rack_apartment_1:
hw_rpi3_bp:
vars:
hw: rpi3_bp
children:
rack_apartment_2:
hw_rpi3_bp:
vars:
hw: rpi3_bp
children:
rack_apartment_3:
# Racks will be named rack_{geo}_{rack}
rack_apartment_0:
doc: |
A bunch of random devices.
Hand-IP'd and mostly not Ansible managed.
vars:
rack: 0
cidr: 10.0.0.0/26
hosts:
sucker.apartment.arrdem.com:
ansible_host: 10.0.0.16
rack_apartment_1:
doc: |
The hosts I initially built out.
I'm gonna assign IP blocks per rack, so
IP assignments are mapped at the rack
level. If a host moves between racks it
should be re-IP'd.
vars:
rack: 1
cidr: 10.0.0.64/29
hosts:
# The modes
logos.apartment.arrdem.com:
ansible_host: 10.0.0.64
ethos.apartment.arrdem.com:
ansible_host: 10.0.0.65
pathos.apartment.arrdem.com:
ansible_host: 10.0.0.66
rack_apartment_2:
doc: |
The raspberry Pi B+ "rack"
vars:
rack: 2
cidr: 10.0.0.72/29
children:
rikis-hopuuj.apartment.arrdem.com:
ansible_host: 10.0.0.72
fidut-vimib.apartment.arrdem.com:
ansible_host: 10.0.0.73
#kipov-rupuh.apartment.arrdem.com:
# ansible_host: 10.0.0.74
rack_apartment_3:
doc: |
The Raspberry Pi B "rack"
Thanks @AndySayler!
(anyone have a 3rd B?)
vars:
rack: 3
cidr: 10.0.0.80/29
children:
...
service_apartment_zookeeper:
doc: |
A little config for and membership of my
ZK cluster. More on this later.
hosts:
logos.apartment.arrdem.com:
zookeeper_id: 1
ethos.apartment.arrdem.com:
zookeeper_id: 2
pathos.apartment.arrdem.com:
zookeeper_id: 3
rikis-hopuuj.apartment.arrdem.com:
zookeeper_id: 4
fidut-vimib.apartment.arrdem.com:
zookeeper_id: 5
It’s a lot, and the power groups especially are pretty messy because power for me doesn’t break down cleanly to rack groups as it would in a “real” datacenter - my power is hand wired and a bit of a rat’s nest.
The really slick thing we can do here is leverage Ansible’s Patterns to make either regex based or set theoretic selections of hosts.
The pattern geo_apartment or hw_rpi3_bp would simply select all hosts in my apartment, or all the Pi3B+ units respectively.
Where this gets interesting is that queries can be multipart unions, intersections and subtractions.
For instance if I had multiple sites, geo_apartment:&hw_rpi3_bp would select all the hosts which are in my apartment and on the Pi3B+ chassis.
Likewise if I had Pi3B+ units deployed in a couple racks across AZs, az_apartment0:&hw_rpi3_bp becomes a relevant query.
Patterns with negation like geo_apartment:&!service_apartment_zookeeper eg.
all hosts in the group not providing zookeeper become relevant for some purposes.
Taking down all of ZK by accident would be bad.
Limitations of inventory
Unfortunately the ansible-inventory tool doesn’t provide a way to test patterns.
Patterns seem to be implemented in the playbook machinery - so you have to work them by hand or build a thing which can compute them.
This is such an obvious oversight that I may yet run off and build such a thing, but that it isn’t in the box is pretty silly.
Out of the box as it were, there aren’t fantastic tools in the Ansible ecosystem for plugging other programs into Ansible’s inventory. The only obvious pattern is to use Ansible to push out updated inventory information all the time which doesn’t scale nicely even to the handful of hosts I have, and blows up your playbook runtimes. It’d be far nicer if there were a standard API for manipulating inventory, and a standard way to publish inventory data so clients on the network can fetch it.
There isn’t an obvious pattern for how to make radical changes like re-hostnaming or re-IPing devices both of which fly in the face of Ansible’s ideas of host identity. This is hard, because Ansible’s inventory construct isn’t aware of its own history. If a device changes IP, Ansible doesn’t know what the old IP was or that the new `` IP is aspirational. That state management has to be built outside Ansible somehow.
While putting hosts in groups ala service_apartment_zookeeper is a great way to accrete state - add a new service and all you have to deal with is adding that one new service - but it doesn’t give you a tool for “garbage collecting” state because again Ansible can’t tell what’s there.
It just barely figures out what new work you want done and leaves everything else alone.
If you want to use Ansible in this way - to implement what’s really an infrastructure-as-code workflow, like other infrastructure-as-code solutions you need a way to retain the “current” state so you can clean up. Other infra as code systems like Terraform maintain a parallel “current state” file which can be used to explain the consequences of changes to inventory and resources, and to then take a patch-based approach to applying changes.
Most crucially, even with full infra-as-code, the history of that infra isn’t transparent to other sources. Infrastructure changes aren’t something you can pub-sub style listen to. Ideally, we should be able to drive live-configured systems (like monitoring!) off of controlled changes to static inventory - thus getting the best of both worlds.
I don’t have a solution to these problems - nor do there seem to be good off-the-shelf tools.
Google has their internal machine database aka mdb of which little is said publicly because it’s an unsexy problem but this is a pretty essential set of problems that need to be solved by anyone who wants to run infrastructure.
Even at the scale of my homelab.
^d